
The idea for this article came while I was at work.
I was talking to an Api provider and he had some very strong ideas on how things should be done. I have built a few APIs myself and suffice to say that we did not think along the same lines. Of course, I wish you good luck if you try to find two developers who agree on pretty much anything, but this really isn’t the point!
So let’s see what the discussion was about. I am a consumer of that API. It is a restful json api.
There were situations when I would fire GET calls with an id to load the details of some entity. The API would return data if there was any, but sometimes that id would not actually be associated with any data. So the solution was to respond with a 404. Of course such a response is valid but in my opinion it should be used in a different manner. We’ll get to that later though. So anything that would return a null object or an empty list would basically return a 404 status instead and myself, the consumer of the API, I am expected to code around this methodology.
Let’s analyse the implications of this. Any dot net client, such as HttpWebRequest or WebClient will throw an exception when encountering a 404 code. If you have to use a front end javascript client, you would have to trap the response with an error method. 404 is considered a big failure which normally means that there is no listener at that particular URI. Your whole request is incorrect and is dealt with as an exception. This of course complicates things a little bit for the consumers.
This is basically why I have an issue with such a method. I am a lazy person ( lazy in a good way ! ) and I like easy and simple things. This isn’t simple anymore because now we have a totally valid request, it just so happens there is no object on the Api side which corresponds to the id that was sent through. So I would lazily return a code 200 with either a null object or a an empty list, if the result is requires that.
This approach of course simplifies things on the client side, everything works, nothing throws an exception and I can nicely inform the client that there is no data for their request.
There is no harm done basically. I was told in no uncertain terms, not only by the API provider, but by one of my own colleagues that this is the correct, standardized approach.
So let’s see, is this actually the right way to do it from a standards point of view?
From a logical point of view, I think my approach makes a lot more sense. It doesn’t mean that I am right, of course. So, let’s look at the standards.
I found a set of standards at jsonapi.org
If you have a look they say this :
A server MUST respond to a successful request to fetch an individual resource or resource collection with a
200 OKresponse.A server MUST respond to a successful request to fetch a resource collection with an array of resource objects or an empty array (
[]) as the response document’s primary data.
A bit lower we can see this :
A server MUST respond to a successful request to fetch an individual resource with a resource object or
nullprovided as the response document’s primary data.
nullis only an appropriate response when the requested URL is one that might correspond to a single resource, but doesn’t currently.
There is more of course and if you keep reading you see that if you happen to request some linked data which should belong to a resource that doesn’t exist in that case it is fine to return a 404 and I completely agree with that.
What I’ve read so far seems to confirm that I was thinking the right way even before reading this spec. Does it make sense to me? Definitely. Does it make sense to anyone else? Well, that is for you, dear reader to let me know, if the subject kept you reading this far!
Let’s not stop here though, let’s look at the w3 spec
According to this spec 404 is defined as follows :
The server has not found anything matching the Request-URI. No indication is given of whether the condition is temporary or permanent. The 410 (Gone) status code SHOULD be used if the server knows, through some internally configurable mechanism, that an old resource is permanently unavailable and has no forwarding address. This status code is commonly used when the server does not wish to reveal exactly why the request has been refused, or when no other response is applicable.
I was totally on the right side here.
It simply does not feel right to return a 404 in such situations when nothing has gone wrong. Yes there could be business rules which state that no such call should ever be made, but there are plenty of valid situations when this can happen. Every time we allow a user to type something to find a booking for example and then use that to try and match it in our back-end. So, there are valid reasons for this to happen. Does it mean the API should blow up with a 404 response? In my opinion, no it shouldn’t.
Now that we’ve cleared this, let’s move on a little. I was reading the w3 spec and I suddenly realized i was doing something wrong myself.
201 Created –
The request has been fulfilled and resulted in a new resource being created. The newly created resource can be referenced by the URI(s) returned in the entity of the response, with the most specific URI for the resource given by a Location header field. The response SHOULD include an entity containing a list of resource characteristics and location(s) from which the user or user agent can choose the one most appropriate. The entity format is specified by the media type given in the Content-Type header field. The origin server MUST create the resource before returning the 201 status code. If the action cannot be carried out immediately, the server SHOULD respond with 202 (Accepted) response instead.
A 201 response MAY contain an ETag response header field indicating the current value of the entity tag for the requested variant just created, see section 14.19.
So when you create data, using a POST, you should return 201, not 200 like I was doing before. I was not following the spec myself!
I am wondering how many API developers actually do this. Please let me know in the comments if you are or not!
So armed with this knowledge, let’s have a look at a little bit of code and try to build a better API. I am going to use VS 2015 and Dot Net 4.5.2. Don’t worry, the code is available on github for your perusing pleasure.
Let’s see what we’ve done in the code.
First, I created a standard Web App, then added MVC and WebApi to it. So far so good. I only want the Json formatter, so I went ahead and wrote a little bit of code in App_Start\WebApiConfig.cs to make sure this happens:
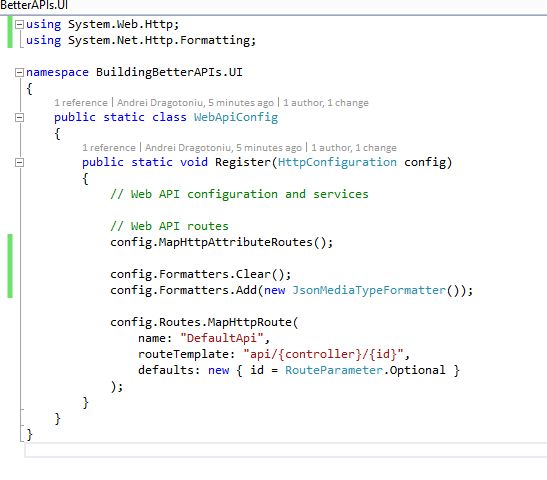
Next I created my WebApi controller and added enough code for the three scenarios I want to present:

As you can see, I have two Get methods, one which blows up with 404 and one which return a 200 Http code together with a null object.
Finally I have a Post which takes an object, simulates a creation method and adds an ID, then returns the whole thing.
Next, I added a little Angular app to show how you can use this API.
The structure of the app looks like this:

Let’s look at these JavaScript files in detail. First the app.js:

As you can see, nothing fancy, we simply create a basic angular app and nothing else.
Next, the dataFactory,js:

It’s just a standard data factory so we can abstract away all the calls to the API.
Finally, the appController,js:

This is where we call all the methods of the API. Look at these calls and their results one by one next.
standardGet:
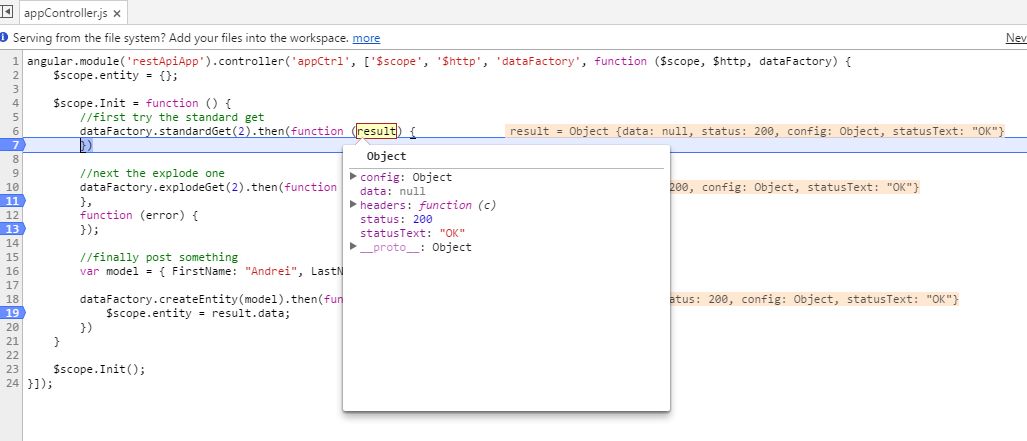
as you can see, it worked nicely, I am getting a 200 HTTP code and my data object is null as expected. Very easy to check.
explodeGet:
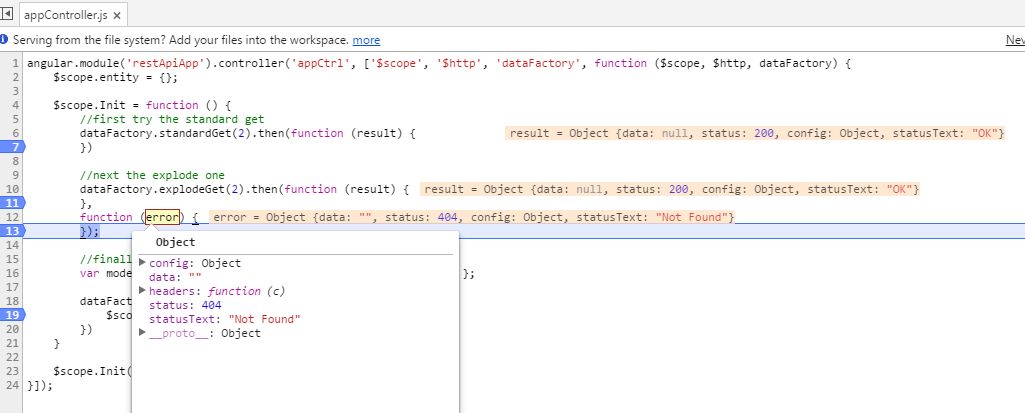
Now i have to have an error function, check the status and if status is 404 I can now conclude there was not data. Doesn’t look as nice as the other option, does it?
Finally the createEntity call:

Looks as expected, I am getting my ID back and the status is 201 Created. I like it, so I am going to keep doing this, unless proven wrong, of course.
I am hoping you found this article interesting and I would be very keen to hear your thoughts on the matter.
